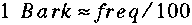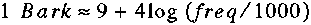Simple
Audio Compression Methods
Psychoacoustics
MPEG
Audio Compression
 Reference: Chapter 6 of Steinmetz and Nahrstedt
Reference: Chapter 6 of Steinmetz and Nahrstedt
- Traditional lossless compression methods (Huffman, LZW, etc.) usually
don't work well on audio compression (the same reason as in image
compression).
The following are some of the Lossy methods:
Human hearing and voice
- Range is about 20 Hz to 20 kHz, most sensitive at 2 to 4 KHz.
- Dynamic range (quietest to loudest) is about 96 dB
- Normal voice range is about 500 Hz to 2 kHz
- Low frequencies are vowels and bass
- High frequencies are consonants
Question: How
sensitive is human hearing?
- Experiment: Put a person in a quiet room. Raise level of 1 kHz tone until
just barely audible. Vary the frequency and plot
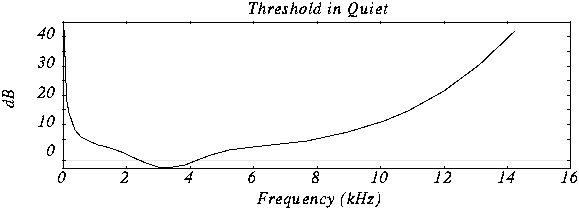
Frequency Masking
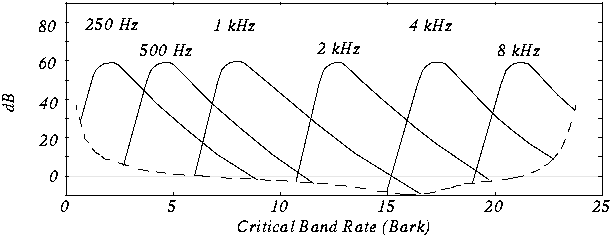
Question: Do receptors interfere with each
other?
- Experiment: Play 1 kHz tone (masking tone) at fixed level
(60 dB). Play test tone at a different level (e.g., 1.1kHz), and raise
level until just distinguishable.
- Vary the frequency of the test tone and plot the threshold when it becomes
audible:
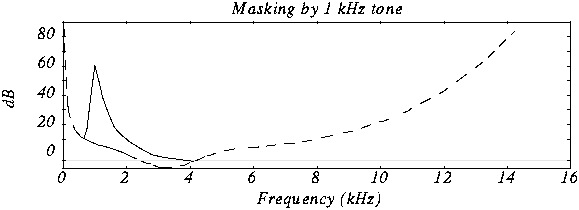
- Repeat for various frequencies of masking tones
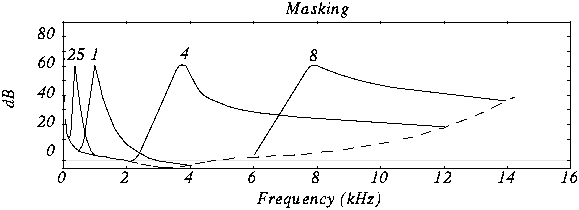
Critical Bands
Barks
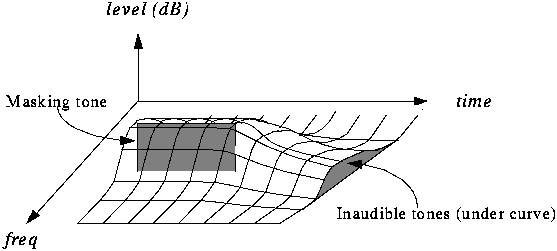
Temporal masking
- If we hear a loud sound, then it stops, it takes a little while until we
can hear a soft tone nearby
- Question: how to quantify?
- Experiment: Play 1 kHz masking tone at 60 dB, plus a test
tone at 1.1 kHz at 40 dB. Test tone can't be heard (it's masked).
Stop masking tone, then stop test tone after a short delay.
Adjust delay time to the shortest time that test tone can be heard (e.g., 5
ms).
Repeat with different level of the test tone and plot:

- Try other frequencies for test tone (masking tone duration constant).
Total effect of masking
Summary
- If we have a loud tone at, say, 1 kHz, then nearby quieter tones are
masked.
- Best compared on critical band scale -- range of masking is about 1
critical band
- Two factors for masking -- frequency masking and temporal masking
- Question: How to use this for compression?
Reference: Davis Pan, "A Tutorial on MPEG/Audio Compression", IEEE
Multimedia, pp. 60-74, 1995.
Some facts
- MPEG-1: 1.5 Mbits/sec for audio and video
About 1.2 Mbits/sec for video, 0.3 Mbits/sec for audio
(Uncompressed CD audio is 44,100 samples/sec * 16 bits/sample * 2 channels
> 1.4 Mbits/sec)
- Compression factor ranging from 2.7 to 24.
- With Compression rate 6:1 (16 bits stereo sampled at 48 KHz is reduced to
256 kbits/sec) and optimal listening conditions, expert listeners could not
distinguish between coded and original audio clips.
- MPEG audio supports sampling frequencies of 32, 44.1 and 48 KHz.
- Supports one or two audio channels in one of the four modes:
- Monophonic -- single audio channel
- Dual-monophonic -- two independent channels (similar to stereo)
- Stereo -- for stereo channels that share bits, but not using
joint-stereo coding
- Joint-stereo -- takes advantage of the correlations between stereo
channels
Steps in algorithm:
- Use convolution filters to divide the audio signal (e.g., 48 kHz sound)
into frequency subbands that approximate the 32 critical bands -->
sub-band filtering.
- Determine amount of masking for each band caused by nearby band using the
results shown above (this is called the psychoacoustic model).
- If the power in a band is below the masking threshold, don't encode it.
- Otherwise, determine number of bits needed to represent the coefficient
such that noise introduced by quantization is below the masking effect (Recall
that 1 bit of quantization introduces about 6 dB of noise).
- Format bitstream
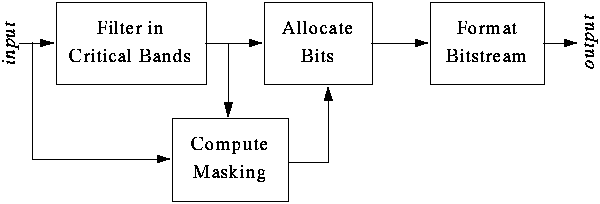
Example:
- After analysis, the first levels of 16 of the 32 bands are these:
----------------------------------------------------------------------
Band 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Level (db) 0 8 12 10 6 2 10 60 35 20 15 2 3 5 3 1
----------------------------------------------------------------------
- If the level of the 8th band is 60dB,
it gives a masking of 12 dB in the 7th band, 15dB in the 9th.
Level in 7th band is 10 dB ( < 12 dB ), so ignore it.
Level in 9th band is 35 dB ( > 15 dB ), so send it.
--> Can encode with up to 2 bits (= 12 dB) of quantization error.
MPEG Layers
- MPEG defines 3 layers for audio. Basic model is same, but codec complexity
increases with each layer.
- Divides data into frames, each of them contains 384 samples, 12 samples
from each of the 32 filtered subbands as shown below.
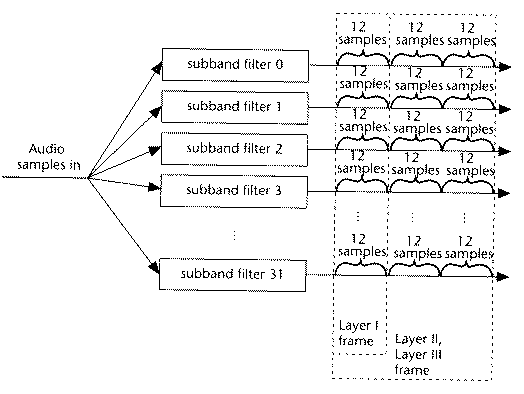
Figure:
Grouping of Subband Samples for Layer 1, 2, and 3
- Layer 1: DCT type filter with one frame and equal frequency spread per
band. Psychoacoustic model only uses frequency masking.
- Layer 2: Use three frames in filter (before, current, next, a total of
1152 samples). This models a little bit of the temporal masking.
- Layer 3: Better critical band filter is used (non-equal frequencies),
psychoacoustic model includes temporal masking effects, takes into account
stereo redundancy, and uses Huffman coder.
Effectiveness of MPEG audio
--------------------------------------------------------------------
Layer Target Ratio Quality @ Quality @ Theoretical
bitrate 64 kbits 128 kbits Min. Delay
--------------------------------------------------------------------
Layer 1 192 kbit 4:1 --- --- 19 ms
Layer 2 128 kbit 6:1 2.1 to 2.6 4+ 35 ms
Layer 3 64 kbit 12:1 3.6 to 3.8 4+ 59 ms
--------------------------------------------------------------------
- 5 = perfect, 4 = just noticeable, 3 = slightly annoying, 2 = annoying, 1 =
very annoying
- Real delay is about 3 times theoretical delay
Further Exploration 
MPEG Resources on
the Web.
Last Updated: 7/8/96
Top
| Chap
4 | CMPT
365 Home Page | CS