CSA302
Lecture 4 - Sound and Audio
Reference: Steinmetz,
R., and Nahrstedt, K. (1995). Multimedia: Computing, Communications &
Applications. Prentice Hall. Chapter 3.
Applications of Sound and Audio
Sound (and its derivatives; speech,
music, etc., generally referred to, if audible to humans, as audio) has a
significant part to play in multimedia applications.
From interacting
through a multi-modal user interface (e.g., Surfing the Web by voice) and text-to-speech
systems (Apple Speech
Technologies), to software agents capable of expressing themselves in
natural language (e.g., VirtualFriend);
Internet-based radio and TV (e.g, RealAudio, and Internet Radio and TV sites);
video-conferencing (e.g., Cu-SeeMe) and
Internet telephony (e.g., VocalTec
Communications); generating computer music, sounds for games, and
computer-controlled musical instruments (e.g., MIDI); to
personalised elevator music and refrigerators that hum along to your mood, audio
is essential.
This lecture presents general properties
of sound, and how to convert it into a bit stream that can be manipulated by a
computer (digitization).
Finally we give an overview of speech
recognition and synthesis
Sound is created by the
vibration of matter and manifests itself when the pressure waves in the air
created by the vibration reach an acoustic device (such as an ear, tape
recorder, microphone, loud speaker, etc.) capable of converting the pressure
waves. [Philosophical issues... the world is completely silent, sounds are only
"inside our heads". If a tree falls in a forest, and there is nothing to hear
it, does it make a sound? In space (a vacuum), nobody hears you scream.]
These vibrations displace the air, and the alterations in pressure propogate
through the air in a wave-like motion (a waveform (see Figure below).
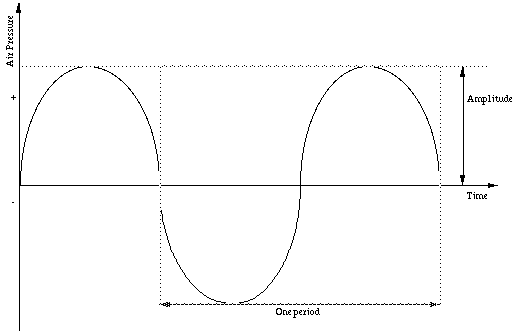
The shape of the waveform that repreats at regular intervals is called a
period, and sounds musical (e.g., a bird singing). A waveform that is not
periodic sounds like noise (e.g., me singing!).
The frequency of a
sound is the number of periods in a second and is measured in hertz (Hz).
1000 Hz = 1 kiloHertz (kHz).
Audible (to humans) frequency occurs in the
20Hz to 20kHz range. Other frequency ranges are:
| Infra-sound |
0 - 20Hz |
| Ultrasound |
20kHz - 1GHz |
| Hypersound |
1GHz - 10THz |
The amplitude of a sound is a property subjectively heard as loudness.
Natural sound occurs as
continuous, and hence, analog, pressure waves. In order to covert these pressure
waves into a representation a computer can manipulate, it is necessary to
digitize them.
An Analog-to-Digital Convervter (ADC) measures the amplitude
of pressure waves at regular time intervals (called samples) to generate
a digital representation of the sound. The reverse conversion, to play digital
sound through an analog device (such as speakers) is performed by a
Digital-to-Analog Converter (DAC).
The number of samples taken per second is
called the sampling rate. CD quality sound is sampled at 44,100 Hz, which
means that it is sampled 44,100 times per second. This appears to be well above
the frequency range of the human ear. However, the Nyquist sampling theorem
states that "For lossless digitization, the sampling rate should be at least
twice the maximum frequency responses." The human ear can hear sound in the
range 20Hz to 20KHz, and the bandwidth (19980Hz) is slightly less than half the
CD standard sampling rate. Following the Nyquist theorem, this means that CD
quality sound can represent frequencies only up to 22,050Hz, which is much
closer to that of human hearing.
Just as the waveform is sampled at discrete
times, the value of the sample taken is also represented as a discrete value.
The resolution or quantization of a sample value is dependent on the
number of bits used to represent the amplitude. The greater the number of bits
used, the better the resolution, but the more storage space is required.
Typically, amplitude is sampled as either 8-bit (resulting in 256 possible
sample values) or 16-bit (yielding 65536 values).
Comparison of Audio Quality vs. Data Rate (from Basics
of Digital Audio)
Quality Sample Rate Bits per Mono/ Data Rate Frequency
(KHz) Sample Stereo (Uncompressed) Band
--------- ----------- -------- -------- ----------------- ------------
Telephone 8 8 Mono 8 KBytes/sec 200-3,400 Hz
AM Radio 11.025 8 Mono 11.0 KBytes/sec
FM Radio 22.050 16 Stereo 88.2 KBytes/sec
CD 44.1 16 Stereo 176.4 KBytes/sec 20-20,000 Hz
DAT 48 16 Stereo 192.0 KBytes/sec 20-20,000 Hz
See An
introduction to MIDI and A Tutorial on MIDI and
Wavetable Music Synthesis for good introductions to MIDI. You should know
how MIDI works at an introductory level, although we will not cover it in the
lectures.
Speech synthesis
(generation) and analysis are important aspects of multimedia systems. As
multi-modal user interfaces become more common, it will become increasingly
important for humans to communicate with computers using spoken language
approaching natural language, and for computer systems to communicate with
humans using artificially generated speech. The human acceptance of
computer-generated speech is dependent on the speech sounding natural and easy
to understand. However, speech synthesis and analysis have a multitude of other
applications. Voice recognition systems are an important class of security
systems; speech synthesis can give those who are vocally impaired a means for
spoken communication. Speech synthesis and analysis are also an important aspect
for computer systems which can be used by illiterate and visually impaired
users.
Speech Synthesis in a Nutshell
Fundamental frequency: the lowest periodic
spectral component of the speech signal. It is present in a voiced sound.
Phone: the smallest speech init, e.g., the m of mat,that
distinguishes one utterance from another in a given
language.
Allophone: the variants of a phone, e.g., the aspirated
p of pit and the unaspirated p of spit.
Morph: the smallest speech unit which carries a meaning itself.
Consider is a morph, but reconsideration is not.
Voiced
sound: a sound generated by the vocal chords, e.g., m, v, and
l.
Unvoiced sound: these sounds are generated while the vocal
chords are open, e.g., f and s.
Real-time speech generation
The easiest way of generating speech in
real-time is by using pre-recorded speech (e.g., MaltaCom's fault-reporting
service, Barbie and
Barney). However, the limitation is that if a word is not pre-recorded, then
it cannot be used. A more flexible, though more time-consuming, solution is to
generate speech by recording individual speech units (of which there are a
finite set) and then generate speech by concatenating the sounds.
However,
consider how you would pronounce the following "Betty is by the sea", normally,
quizzically, and agitatedly. Also consider how "an arm and a leg" would sound
with a British accent and with a New York accent. Stress (together with melody
called prosody) also plays a large part in sound generation. However,
getting the prosody right is still a challenge, and consequently
computer-generated speech can sound quite unnatural. Apart from this high-level
problem, there are also problems with words which follow each other. Consider
the word the. The sound changes depending on whether the following word
starts with a vowel or a consonent. These problems can be overcome using
coarticulation rules over phone order. Other problems which influence
pronounciation include ambiguity. Consider the word lead in the
following sentences: "The general lead his army to famous victory", and "In
parks, dogs should always be kept on a lead". Although some pronounciations can
be disambiguated using syntactic analysis - at face value, in the first sentence
lead is a verb in the 3rd person singular past tense and in the second it
is a noun, on other occasions, semantic analysis is necessary. Despite these
problems, it is possible to generate speech to an acceptible level of
quality.
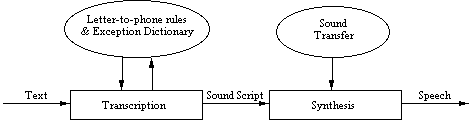
The figure below (from Steinmetz
and Nahrstedt, pg. 46) shows the components of a speech synthesis system.
Speech Analysis
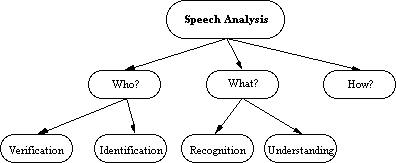
The figure above (from Steinmetz
and Nahrstedt, pg. 47) identifies the research areas concened with speech
analysis.
The primary goal of speech analysis is to correctly determine
individual words with a probability <= 1. Reasons why systems are less
accurate than this are due to ambient noise (humans are remarkably good at
speech recognition even in noisy environments), word sense ambiguity ("there"
and "their", for example), dialect and stress.
Once individual words in a
sentence have been recognised, the probability of recognising the sentence
correctly is the probability of recognising the individual words multiplied by
the number of words in the sentence. For example, if the probability of
recognising individual words is 0.95, then the probability of correctly
recognising a 3 word sentence is 0.875. Factors which reduce the probability of
sentences being correctly recognised include correctly determining word
boundaries (compare "An arm and a leg" spoken with a British and New York accent
- although, obviously, the misinterpretation is by British listeners to a New
York accent!), semantics, and time normalization. The same sentence can be
spoken quickly or slowly - as can individual words in an utterance.
Speech
recognition systems are divided into speaker-independent recognition
systems and speaker-dependent recognition systems. The main
differences are that although speaker-independent systems can be used by many
different speakers without training, only a limited number of words are
recognised (e.g., some of British Telecom's telephone services which can
recognise only the words "Yes" and "No" - but compare this to MaltaCom's
services which require a "9" or "0" tone to be sent in response to questions),
whereas with a speaker-dependent system, after training, it can recognise an
extensive vocabularly in excess of 25,000 words.
Related Links
Basics
of Digital Audio
YAHOO's Multimedia:Sound
Page
Back to the index
for this course.
In case of any difficulties or for further information
e-mail cstaff@cs.um.edu.mt
Date last amended: Tuesday, 24 October, 2000